Wildfire monitoring from satellite data
We had a great time hosting our "Getting started with Data Science for clean technology professionals" webinar - a big thank you to everyone who registered and asked all those interesting questions! If you're interested in getting the recording, it's now available for download on our website.
And now, back to our regular posts on how data science is used in different clean tech fields!
There's been a lot of news about the wildfires in the Amazon and the consequences for the planet, so let's talk about wildfire detection and how it's done. Wildfires, and in particular the Amazon fires, are detected using data from a wide range of satellites - NASA's array, the EU's Copernicus, Brazil's Terra satellites, Japan's Himawari-8, and CubeSats among others. But what exactly do these satellites see and how can you identify a wildfire from the data?
Typically, satellites carry multi-spectral cameras or sensors on board. As the satellite passes over an area on the Earth's surface, the camera takes several photographs in different wavelengths - visible (the RGB wavelengths), infrared, thermal-infrared, microwave and part of the UV region. This is done because different surfaces reflect different wavelengths and by using a combination of wavelengths we can figure out whether something is water, fire, a grassland, forest and so on.
Processing this data so that all the features can be identified is what the field of remote sensing is all about - and this involves several algorithms ranging from image processing to machine learning. Typically, the models that identify these features are then validated using data from the ground. For example, you'll often see crop data from NASA with an estimate of the area covered by a certain crop (say grapes in California), together with an error or uncertainty value. This value is the difference between the model estimates based on the image data from the satellite and what was seen on the ground when the data was validated. If there was a lot of data collected at the ground, then the model has a lower error because there's more training data available to improve model prediction. That's why crops like corn, soy, wheat and rice have lower errors associated with them compared to specialty crops.
The same thing holds true for detecting fires. There are several factors that govern fire detection - area, spread, temperature, duration - but, the first step is - can you detect an area where the temperature is higher than the surroundings? Thermal imaging comes in handy here - with data from the infrared spectrum allowing us to identify areas with different temperatures.
This is the basic step, with several other questions that need to be solved before classifying something as a fire. For example, how much difference in temperature is needed before we can identify it as a fire as opposed to some other phenomenon? And that's where other models, such as machine learning and/or simulations of fires based on known behavior come in. Given the large dataset of wildfires that's available, we can train machine learning algorithms to quickly identify patterns that look like fires - combine them with physical simulations that account for additional real-time factors like wind and rain, and develop a model that can predict a fire with significant accuracy.
An example of a fire detection algorithm would be this model that was developed by researchers in Asia using the Himawari-8 imagery:
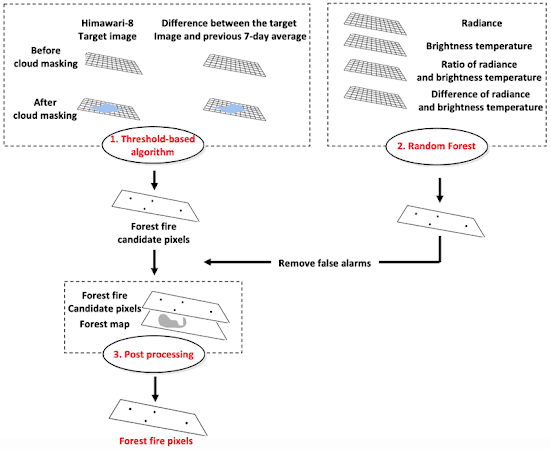
3-STEP FOREST FIRE DETECTION ALGORITHM (I.E., THRESHOLDING, MACHINE LEARNING-BASED MODELING, AND POST PROCESSING) USING HIMAWARI-8 GEOSTATIONARY SATELLITE DATA OVER SOUTH KOREA. FIGURE: JANG, E., KANG, Y., IM, J., LEE, D. W., YOON, J., & KIM, S. K. (2019). DETECTION AND MONITORING OF FOREST FIRES USING HIMAWARI-8 GEOSTATIONARY SATELLITE DATA IN SOUTH KOREA. REMOTE SENSING, 11(3), 271.
The final "forest fire pixels" are then visualized on a map as a cluster of dots or a polygon - and that's what we see in the news.