Clean Technology Meets Data Science 101: Part 2
The Harvard Business Review called the job of a Data Scientist “the sexiest job of the 21stcentury”. It’s a field that been booming in the last five years or so, with applications in multiple sectors – from finance to health to computer science to space and more recently to clean technology.
Data Science or Big Data as it’s sometimes being called is a relatively new term that refers to processes and methods to generate, process and develop insights from data. With more people coming online these days and generating large volumes of data, we’ve had to use methods and techniques from a wide range of disciplines to handle the speed, volume and variety of the data and understand what the data are telling us. That’s where the whole concept of “Big Data” or Data Science has come about – it’s a multi-disciplinary field that uses a basket of methods and tools from different fields, especially statistics and machine learning.
Some of the topics I talk about in my list below are now accepted as being integral to a data scientist’s work – the others are emerging areas that are going to be producing large amounts of data and are being used in some way in the clean technology field.
- Statistics: The traditional way of dealing with data – looking at hypothesis testing, population distributions, time-series analysis and sampling strategies. It’s been used by companies to test marketing campaigns and to understand user behavior on the internet. In the clean technology field, statistics is essential to understanding how effective your technology is – for example, is your crop in part of a field performing better than in another part because you changed your fertilizer?
- Machine Learning: This comes from computer science – how can we use data to teach machines about a system, so that they can identify and build similar systems without our input? It’s a very large toolkit ranging from the simplest algorithms like regression analysis to complex ones like multi-level neural networks used in deep learning. It’s used by academics and companies to solve all kinds of problems in clean tech – designing better water treatment systems, improving energy efficiency and so on.
Both statistics and machine learning form the core of a data scientist’s toolkit.
The next 3 areas use machine learning algorithms, but are used so often in data science that they are treated as independent areas.
- Natural Language Processing: NLP as it is commonly called uses machine learning algorithms to derive rules about text generated by humans. The algorithms can derive hard rules as well as more probabilistic models – it’s what the big tech companies use to suggest searches or analyze sentiment based on reviews. In clean tech, NLP is often used to understand consumer behavior and improve conservation or energy efficiency goals.
- Graph Theory and Network Analysis: This is one of the most powerful tools in the data science toolkit. In this, graphs are built using nodes and the relationships or links between them in order to extract answers to questions about the system. It’s what powers the algorithm behind Google Search and Facebook’s Knowledge Graph. In clean tech, network analysis is often used in planning smart cities and in building better transportation networks.
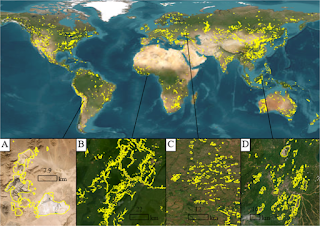
- Remote Sensing: Remote sensing uses satellites to capture data about the Earth and then processes the images using a combination of machine learning algorithms and other tools. These images can then be parsed and analyzed to yield information – either independently or in combination with other data sets. It’s one of the most commonly used tools in clean technology these days – it’s used to understand how agriculture can be improved, better manage water systems and even look at populations and development.
While the first five areas have focused on how to analyze data once we have it, the next two areas are more about how to generate the data itself.
- Sensors and the Internet of Things (IoT): Sensors have been used in clean technology for a long time – to measure water levels, pollutants, automate factories and so on. The difference between the sensors that are being built these days is that sensors today are often smaller than previous generations and most importantly, can send data to the internet where it can be accessed remotely. Or in other words, sensors are now becoming part of an “Internet of Things”. So, as a clean tech specialist, you no longer need to wait to collect your sensor to see what the data are like – you can watch in real-time. This is an area that is expanding rapidly as new tools are being developed rapidly and are being tested to solve new problems.
- Robots, Drones and Virtual Reality: As robotics improves, we see more and more use of robots and drones in clean technology. For example, the plugging of the well that caused the Deepwater Horizon oil spill used robots that could work at the depths needed. Another example is the Apple’s recycling robot which removes various components from used phones and computers and separates them for reuse and recycling. The use of drones (unmanned aircraft) is also expanding to add more data to that gained from satellites. Similarly, while Virtual Reality hasn’t yet taken off completely in clean tech, there are several applications that are being tested at this time.
The next two areas focus on how to process the data once it’s generated.
- Cloud computing, Map Reduce and Databases: These are very classic computer engineering problems – how to store data and how to access the data efficiently. As a data scientist, understanding the systems where the data are stored is essential to being able to extract the data that are actually needed to solve the problem. Traditionally, data was stored in databases that had indexes which could be queried. While these are still being used, other systems have been developed that do away with indexes and use other search techniques to find the data. One of the most powerful systems was developed by Google and is called MapReduce – the open source version of it is commonly called Hadoop.
- Security and data mining: Again, these are questions that more typically concern a computer scientist or engineer – how to make sure that your data is secure and cannot be hacked. In the clean tech field however, as sensors and IoT become more widely used – data security and the security of the devices themselves become important. It’s critical that the water treatment plant for example cannot be hacked and manipulated remotely – or that the power plant cannot be sabotaged remotely.
The last area looks at data visualization. Once the data has been generated and analyzed, the information gained has to be communicated easily and efficiently. Dashboards are often used to present results at a high level, however maps are the most useful in clean technology problems.
- Mapping and Geographic Information Systems: These are the most commonly used visualization systems in clean technology. While they are often stand alone systems – with the advent of Google Maps, many companies are attempting to build these systems in the cloud. A visual map of what is happening is often the easiest way to communicate the problem being studied as well as the results.